
FAQ по расчету критерия Фишера (угловое преобразование Фишера) |
 |
|
|
|||||||||
• Вход | Поиск | Правила форума •
|
|
 |
FAQ по расчету критерия Фишера (угловое преобразование Фишера) |
 23.10.2008, 9:18 23.10.2008, 9:18
|
|
|
FAQ по расчету критерия Фишера (угловое преобразование Фишера) Автоматический расчет можно произвести на странице критерия Фишера О скрипте «Расчет углового преобразования Фишера» Настоящий скрипт позволяет с легкостью рассчитать достоверность различий между процентными долями двух выборок, в которых зарегистрирован интересующий эффект. Шаг 1. Необходимо заполнить 4 ячейки данными, соответствующими количеству испытуемых в первой группе (первая строка) и второй группы (вторая строка). В первую колонку вводятся испытуемые, у которых обнаружен эффект, а в вторую колонку испытуемые, у которых эффект отсутствует. Обратите внимание, что вводятся только положительные числа по одному на строку. Пробелы и пропуски строк не допустимы (скрипт выдаст ошибку). Также скрипт может выдасть ошибку в том случае, если Ваши данные попадут в диапазон ограничений (читай ниже). После заполнения, нажимаете кнопку «Шаг 2» для получения результата расчетов. Шаг 2. При правильном выполнении шага 1, Вы получаете результаты автоматического расчета! Будет выведена таблица с вводимыми Вами количеством испытуемых, а в скобках их процентная доля. Ниже таблицы выведено эмпирическое значение ф, рассчитанное по формуле, а также график оси значимости (для наглядности), с цветовым обозначением той области, в которую попадает результат. Так, если область красная, то полученный результат попал в зону «незначимости» и, следовательно, принимается гипотеза Н0. Назначение и описание критерия Фишера Критерий Фишера предназначен для сопоставления двух выборок по частоте встречаемости интересующего исследователя эффекта. Критерий оценивает достоверность различий между процентными долями двух выборок, в которых зарегистрирован интересующий нас эффект. Суть углового преобразования Фишера состоит в переводе процентных долей в величины центрального угла , который измеряется в радианах. Большей процентной доле будет соответствовать больший угол φ, а меньшей доле - меньший угол, но соотношения здесь не линейные: φ = 2*arcsin( 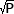 ), где P - процентная доля, выраженная в долях единицы. ), где P - процентная доля, выраженная в долях единицы.При увеличении расхождения между углами φ1 и φ2 и увеличения численности выборок значение критерия возрастает. Чем больше величина φ*, тем более вероятно, что различия достоверны. Гипотезы критерия Фишера H0: Доля лиц, у которых проявляется исследуемый эффект, в выборке 1 не больше, чем в выборке 2. H1: Доля лиц, у которых проявляется исследуемый эффект, в выборке 1 больше, чем в выборке 2. Ограничения критерия Фишера Настоящий скрипт учитывает эти ограничения! 1. Ни одна из сопоставляемых долей не должна быть равной нулю. Формально нет препятствий для применения метода φ в случаях, когда доля наблюдений в одной из выборок равна 0. Однако в этих случаях результат может оказаться неоправданно завышенным. 2. Верхний предел в критерии φ отсутствует - выборки могут быть сколь угодно большими. Нижний предел - 2 наблюдения в одной из выборок. Однако должны соблюдаться следующие соотношения в численности двух выборок: а) если в одной выборке всего 2 наблюдения, то во второй должно быть не менее 30: n1=2 -> n2≥30; б) если в одной из выборок всего 3 наблюдения, то во второй должно быть не менее 7: n1=3 -> n2≥7; в) если в одной из выборок всего 4 наблюдения, то во второй должно быть не менее 5: n1=4 -> n2≥5; г) при n1, n2≥5 возможны любые сопоставления. В принципе возможно и сопоставление выборок, не отвечающих этому условию, например, с соотношением n1=2, n2=15 но в этих случаях не удастся выявить достоверных различий (а настоящий скрипт для автоматического расчета выдаст ошибку). |
|
|
|
|
23.10.2008, 15:22
|
|
|
Пример решения (Данный пример взят из книги Е. Сидоренко «Методы математической обработки в психологии». С другими примерами можете ознакомиться в этой книге.) Пример 1 - сопоставление выборок по качественно определяемому признаку В данном варианте использования критерия мы сравниваем процент испытуемых в одной выборке, характеризующихся каким-либо качеством, с процентом испытуемых в другой выборке, характеризующихся тем же качеством. Допустим, нас интересует, различаются ли две группы студентов по успешности решения новой экспериментальной задачи. В первой группе из 20 человек с нею справились 12 человек, а во второй выборке из 25 человек - 10. Поскольку нас интересует факт решения задачи, будем считать "эффектом" успех в решении экспериментальной задачи, а отсутствием эффекта - неудачу в ее решении. Сформулируем гипотезы. Н0: Доля лиц, справившихся с задачей, в первой группе не больше, чем во второй группе. Н1: Доля лиц, справившихся с задачей, в первой группе больше, чем во второй группе. Теперь введем данные в четырехклеточную таблицу, которая фактически представляет собой таблицу эмпирических частот по двум значениям признака: "есть эффект - нет эффекта". Соответственно, в первую ячейку первой строки (группы 1) мы вписываем 12 (кол-во испытуемых, у которых «есть эффект»), во вторую ячейку первой строки (1 группы) вписываем 8 человек у которых «нет эффекта» (20 – 12 = 8). Далее, в первую ячейку второй строки (группы 2) вводим 10 (кол-во испытуемых, у которых «есть эффект»), во вторую, соответственно, оставшиеся 15 человек (потому как 25 – 10 = 15). Нажимаем кнопку «Шаг 2» и получаем ответ! Ответ из себя представляет эмпирическое значение ф*=1.343, рассчитанное по формуле, а также выбранную гипотезу (H0 или H1), - в нашем примере это гипотеза H0. Для наглядности рисуется ось значимости с выделенной областью, куда попадает полученный ответ. Все! Если есть вопросы по работе скрипта, замечания, пишите здесь… |
|
|
24.5.2009, 0:22
|
|
|
спасибо огромное!! отличный скрипт! курсовая спасена!
|
|
|
|
© PSYCHOL-OK: Психологическая помощь, 2006 - 2025 г. | Политика конфиденциальности | Условия использования материалов сайта | Сотрудничество | Администрация